


It’s my first blog of the year, and the topic is internet data safety – Part 2: Electric Boogaloo. If you read my earlier posts about internet safety and digital privacy, then you’re probably already aware of how the internet accesses and utilizes user data for third parties. Europe instituted specific laws to protect their users’ privacy online, and now the US is adopting similar laws, state by state. This conversation is once again ramping up due to third-party cookies being phased out by Google and the emergence of AI data scraping.
How it effects internet users
The TL;DR of the current AI controversy is that user data (personal information such as name, email, location, search queries, and spending habits) is being fed into machine-learning technology to create new pieces of content – from novels to art to the voices and portrayals of actors (oftentimes without their consent or knowledge). Most artists and creators are opposed to having AI use their original work based around a prompt from another user. During the writer’s and actor’s strikes of 2023, the use of AI was one of the key points both unions wished to negotiate on. If AI could write screenplays with less time and money than an actual human, then what was the point of hiring a writer? If actors could appear in movies using AI, why offer them the official role?
Proponents of AI praise the efficiency and low cost of putting technology to work; the benefits of which are meant to make employees more efficient at their jobs. New tech is always given the Shiny New Thing(tm) treatment, for better or worse. Remember crypto and those weird NFT monkeys? AI is now the next best thing to happen to tech for most marketing agencies and tech startups. The investment opportunities are there for those with the funds and patience to play the long game.
How it effects WordPress and Tumblr users
An internal conversation made its way to the public about a deal Automattic is making with AI companies Midjourney and OpenAI, which revealed the company’s plans to sell user data for AI training purposes. Automattic is the current owner of the blogging platforms Tumblr and WordPress (which is the platform this blog is using), and made a quick statement about the deal plans. In it, they discussed an opt-out option for users who don’t want their content being used to train AI that will “discourage crawling by AI companies” and hopefully prevent their data from being sold to a third party. Right? Well, about that…
The internal documents also share that user data from Tumblr has already been compiled and possibly available to those third parties anyway. This data contained information that wasn’t supposed to be scraped, which is an even bigger mess. So while users are able to opt out now, they were previously opted in without even knowing it. Whatever data has been handed over is now up to the third parties to “ignore” or use however they want. It’s still worthwhile to take the extra step of opting out of this process until better security measures are in place to protect users’ privacy online.
What you can do
Instructions to discourage search engine crawling and prevent third party sharing have been posted in Tumblr’s help center about account security and documentation regarding WordPress.com sites are forthcoming. Thankfully, I’ve done both and can walk you through the steps.
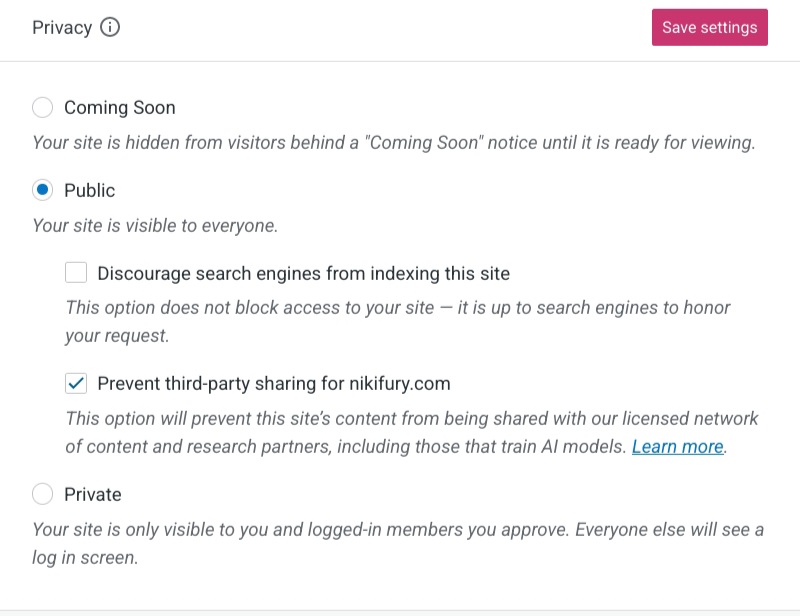
From your admin dashboard, navigate to settings -> general and scroll down to see the privacy options. You can display a “Coming soon” page while working on your site, set it to private so only logged in users can see it, or have it public. When set to public, you have the option to opt out of search results (if you don’t want your site to be found through a query) and/or opt out of data scraping for third parties. Note that both of these options say “discourage” and leaves it up to third parties like search engines and AI companies to honor the request. This isn’t a guarantee that your blog won’t appear in search results or be fed to AI machines, so you may want to take extra precautions and additional security measures.
Further privacy protection
Artists have been preventing their work from being used to train AI with new tools, such as Nightshade and Glaze. In light of Google Docs also admitting to data scraping to train their AI generative service, writers have been searching for different word document platforms. These include setting up a cloud service like Nextcloud and even using a different operating system than Microsoft Windows, such as Linux (which I’ve honestly been looking into). Other options for authors specifically include Scrivener, Novlr, Reedsy, and other writing specific platforms.
If you store your work on a website, such as a writing blog or art portfolio, you can add more security with two-factor authentication for user logins, Secure Sockets Layer (SSL) certificates for a more secure connection with encryption protocol, as well as using security services from your website platform or host (GoDaddy offers SSL and other security products to hosted sites). I also recommend having strong firewall protection, anti-virus software (such as Kaspersky or Trend Micro). Some of these security measures are primarily used for blocking spam bots, guarding against DDoS attacks, and ensuring a smooth recovery of your site and it’s content if it gets compromised, but they are also powerful tools to prevent hacking and data theft.

Go forth and prosper
I could go on and on about cybersecurity and data privacy, but other developers and tech companies can go more in-depth based on your specific needs. I encourage everyone to learn more about how machine-generated content is created, how data scraping works, and the best security measures to protect your work and your privacy.

Leave a comment